Foundation models
这里列出一些近年来关于大模型的总结、调研,还有相关顶会论文。总结顶会论文的原因在于,在我看来大模型(或基础模型)大多都是在工程领域的创新,如何利用工程创新,助力是科学创新。中间的桥梁应该被找到。
注:有些调研直接截图了平日的工作汇报,注意与最新的工作进展及时同步。
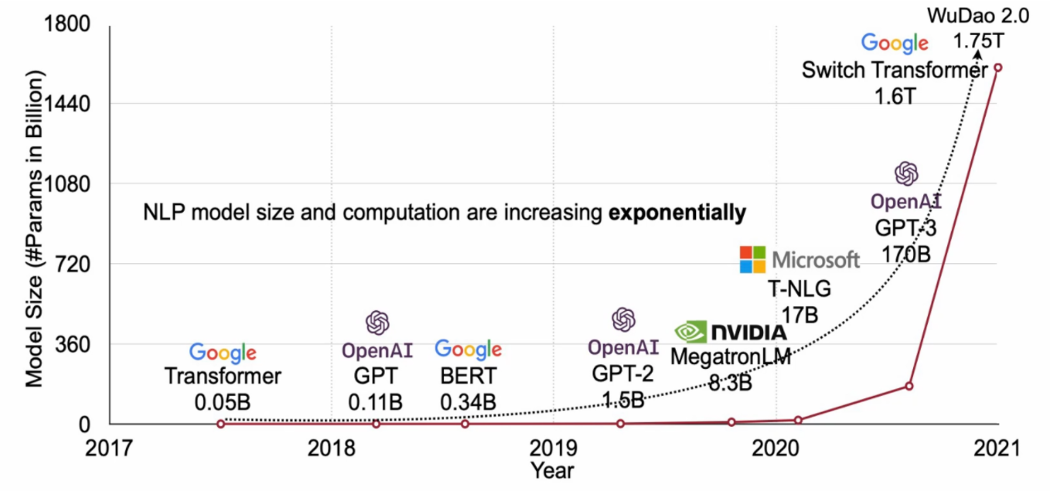
1. Large Language Model, after GPT-3
概括:超大参数规模的模型,并利用超大规模数据,大多以self-supervised方式进行训练,来学习数据的通用表征。后续通过prompt、fine-tune等迁移学习方法适应不同下游任务的通用模型范式。
目前foundation model的应用领域以及下游任务包括
NLP(成熟)
下游任务:翻译、问答、语义总结,等
代表模型:GPT-3,LaMDA、PaLM、BLOOM,等
CV
下游任务:文生图、文生视频、图片描述、风格迁移,等
代表模型:DALL-E 2、Imagen、Parti,等
Foundation model的特点:emergence, homogenization
Emergence:除“隐生性”,即模型学习到的表征是隐性的,而非人类指定的。还有一种解释为“涌现性”,即:模型参数规模上,由量变引起质变的过程,一些模型的特性在小模型上不具备,而当参数规模扩大后才会显露的特性。
Homogenization:foundation model的基础模型呈现同质化趋势,目前NLP大模型几乎都由transformer结构中改变而来。
Foundation model对下游任务的适配
Fine-tune:针对特定的任务,利用特定的标签数据对模型参数进行fine-tune,得到的模型将只在特定任务上有较好性能,无法用于其他任务
Prompt:对输入的文本按照特定模板进行处理,通过恰当的方式重新定义下游任务,使之更适配预训练语言模型的形式,使之回忆起预训练时的知识
Few-shot learning setting
Zero-shot learning setting
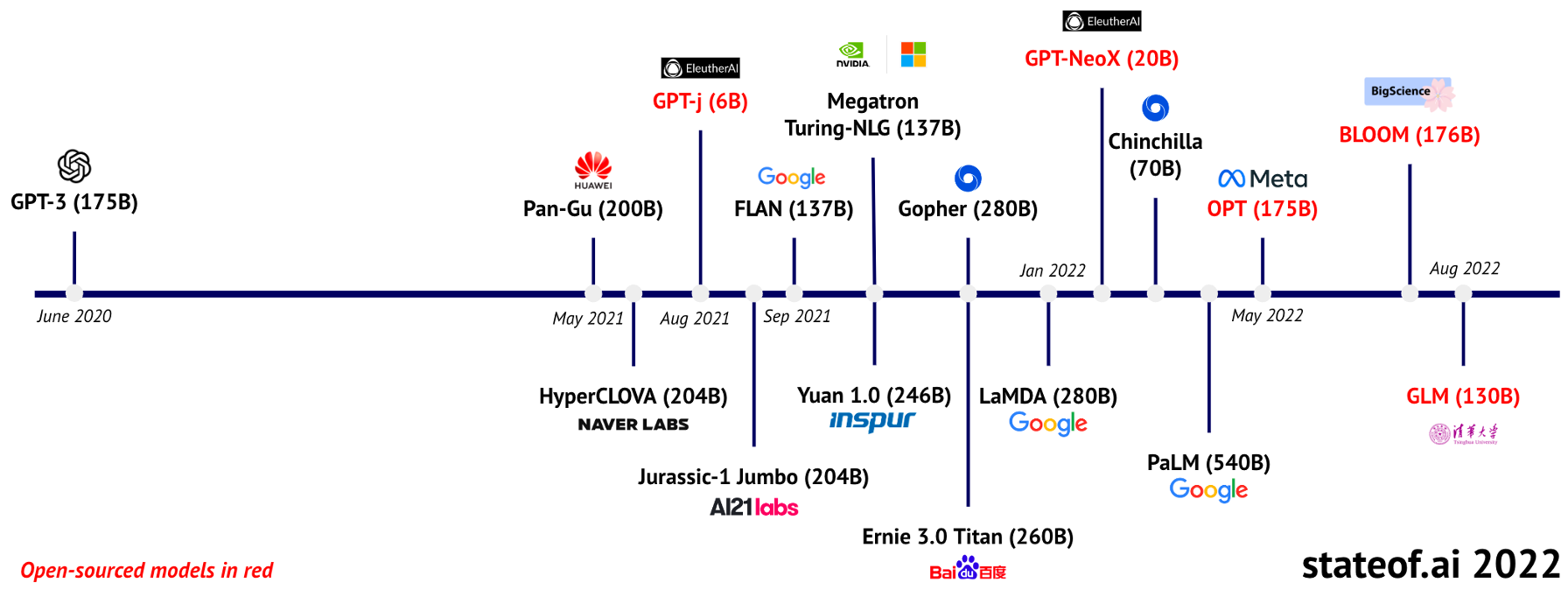
1.1 大模型调研
上述模型的体量总结如下表
| 模型 | 训练时间 | 训练空间 | 模型大小 | 优化器+模型大小 | 参数量 | 数据量 | 模型结构 |
|---|---|---|---|---|---|---|---|
| GPT-3 (OpenAI) | 3.14e11 TFLOPS | 175B | 45TB (raw data) 570GB | Sparse Transformer | |||
| PanGu (Huawei, CN) | 2048 Ascend 910 AI processors | 750GB | 200B | 1.1T | Transformer | ||
| GPT-J (EleutherAI) | 1.5e10 TFLOPs | 9GB | 61GB | 6B | 825G (raw data) | Sparse Transformer (like GPT-3) | |
| Ernie 3.0 Titan (Baidu) | 3.14e11 TFLOPS | Nvidia V100 GPU and Ascend 910 NPU clusters (分布式) | 2.1TB | 260B | Transformer-XL | ||
| GPT-NeoX (EleutherAI) | 39GB | 268GB | 20B | 825G (raw data) | Sparse Transformer (like GPT-3) | ||
| OPT (Meta) | 4.48e10 TFLOPs* | 992 80GB A100 GPUs | 175B | 800GB (raw data) | Transformer | ||
| BLOOM (BigScience) | 3.5 month | 384 A100 80GB GPUs (48 nodes) | 0.33TB | 2.3TB | 176B | Transformer (like GPT-2) | |
| GLM-130B (Tsinghua) | 2 month | 96 NVIDIA DGX-A100 (8*40G) GPU nodes | 130B | 2.3T (raw data) | Transformer (like GLM) |
1.1.1 大模型研究进展更新
LLaMA [Meta AI, 2023.02.23]
模型亮点
着眼于高效推理的大模型,以小规模参数、大规模 token,借助公开数据集,使用常规优化器训练的开源大模型
在不同规模的参数量上训练不同规模的模型
LLaMA-13B 的性能优于 GPT3-130B,但仅有约0.1倍参数量
LLaMA-65B 的性能比肩 Chinchilla-70B、PaLM-540B
重点评估了模型的 biases and toxicity
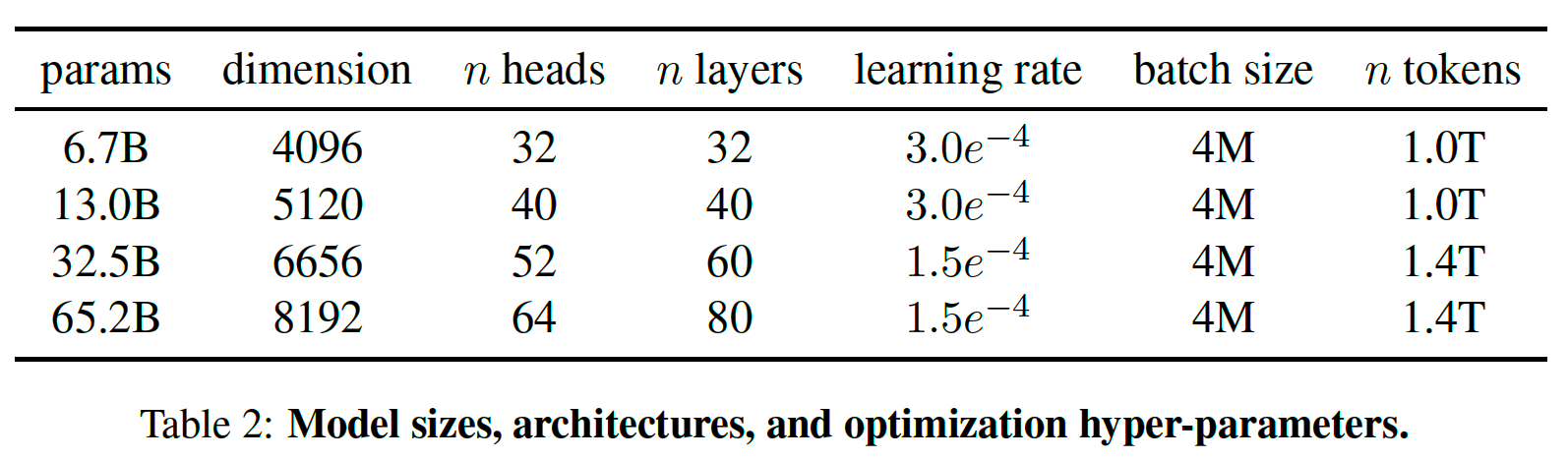
模型架构
骨架模型:Transformer
结构修改:
[GPT3] 在每个 Transformer 子层,normalize (RMSNorm) 输入,而非输出
[PaLM] 用 SwiGLU 取代 ReLU;记 attention 层维度为 $d_{model}=d_{head}\times n_{head}$,feed-forward 层维度为 $d_{ff}=\frac{2}{3} 4d_{model}$ ,而非 $4d_{model}$
[GPTNeo] Embedding 方法采用 rotary positional embeddings (RoPE),而非absolute positional embeddings
训练、推理空间
训练:2048 A100 GPU with 80GB of RAM
推理:LLaMA-13B可推理于一张 V100 GPU
1.1.2 大模型基础架构
目前在NLP领域被成功训练并大规模应用的模型,都是基于Transformer的self-attention架构的:
Autoregressive(仅包含decoder):自回归模型的代表是GPT。本质上是一个从左到右的语言模型,训练目标是从左到右的文本生成。
- 常用于无条件长文本生成(对话生成、故事生成等),但缺点是单向注意力机制,不利于NLU(自然语言理解)任务。
Autoencoding(仅包含encoder):代表模型是BERT、ALBERT、DeBERTa 。自编码模型是通过去噪任务(如利用掩码语言模型)学习双向的上下文编码器,训练目标是对文本进行随机掩码,然后预测被掩码的词。
- 常用于自然语言理解(事实推断、语法分析、分类等),缺点是不能直接用于文本生成。
Encoder-decoder(完整的Transformer结构):代表模型是T5、BART。包含一个编码器和一个解码器,接受一段文本,从左到右的生成另一段文本。
- 常用于有条件的生成任务(摘要生成、对话等)。缺点是比BERT-based模型在同性能下需要更多参数。
Hybird-model:GLM
还有一些模型结合了transformer-based模型,以及其他模型,用于改善transformer缺乏长期记忆的缺点。
与GNN结合: CogQA [1]
与knowledge graph结合: OAG-BERT [2]
[1] Ding, M., Zhou, C., Chen, Q., Yang, H., & Tang, J. (2019, July). Cognitive Graph for Multi-Hop Reading Comprehension at Scale. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (pp. 2694-2703).
[2] Liu, X., Yin, D., Zhang, X., Su, K., Wu, K., Yang, H., & Tang, J. (2021). Oag-bert: Pre-train heterogeneous entity-augmented academic language models. arXiv preprint arXiv:2103.02410.
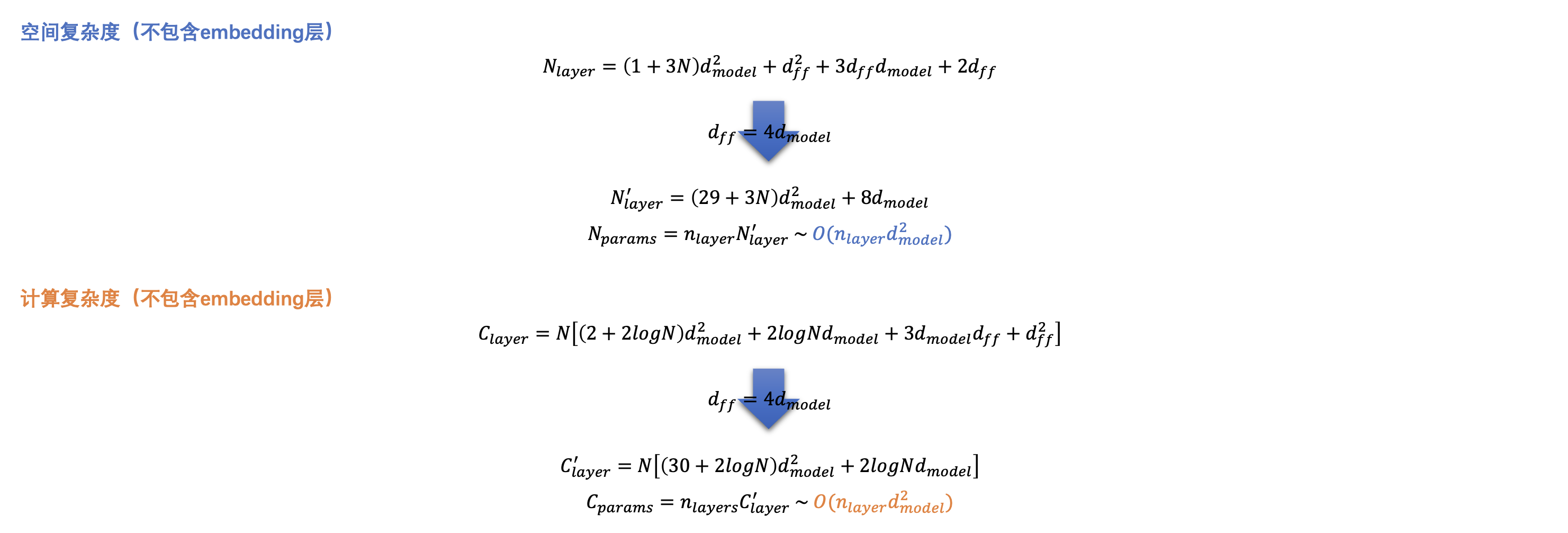
1.2 大模型复杂度分析
深度学习的保存模型里包含所有trainable variables的精确值。下文以sparse transformer为例,分析该模型的空间复杂度、计算复杂度。
Self-attention的隐空间维度为$d_{model}$,head数目为$n_{head}$,则每个head的维度为$d_{head}=d_{model}/n_{head} $。Feed-forward的隐空间维度为$d_{ff}$
记输入到下述的一层sparse transformer的数据为$\mathbf{X} \in \mathbb{R}^{N × d_{model}}$,$N$为输入的句子长度。
记self-attention的层数为$n_{layer}$
2. How to train a big model, from zero to one
在specific-domain构建一个大模型,首先需要
确定下游任务
下游任务决定了模型的预训练任务:预训练任务应当challenge,且贴近下游任务。分析下游任务主要分析token-wise还是sentence-wise relationship,可以按需选择预训练任务。
下游任务决定了模型骨架:模型注重NLU还是NLG?
确定模型骨架:从Autoencoding / Autoregressive / Encoder-decoder中选择合适的框架
确定模型预训练任务
从下游任务和预训练任务出发,处理并准备语料
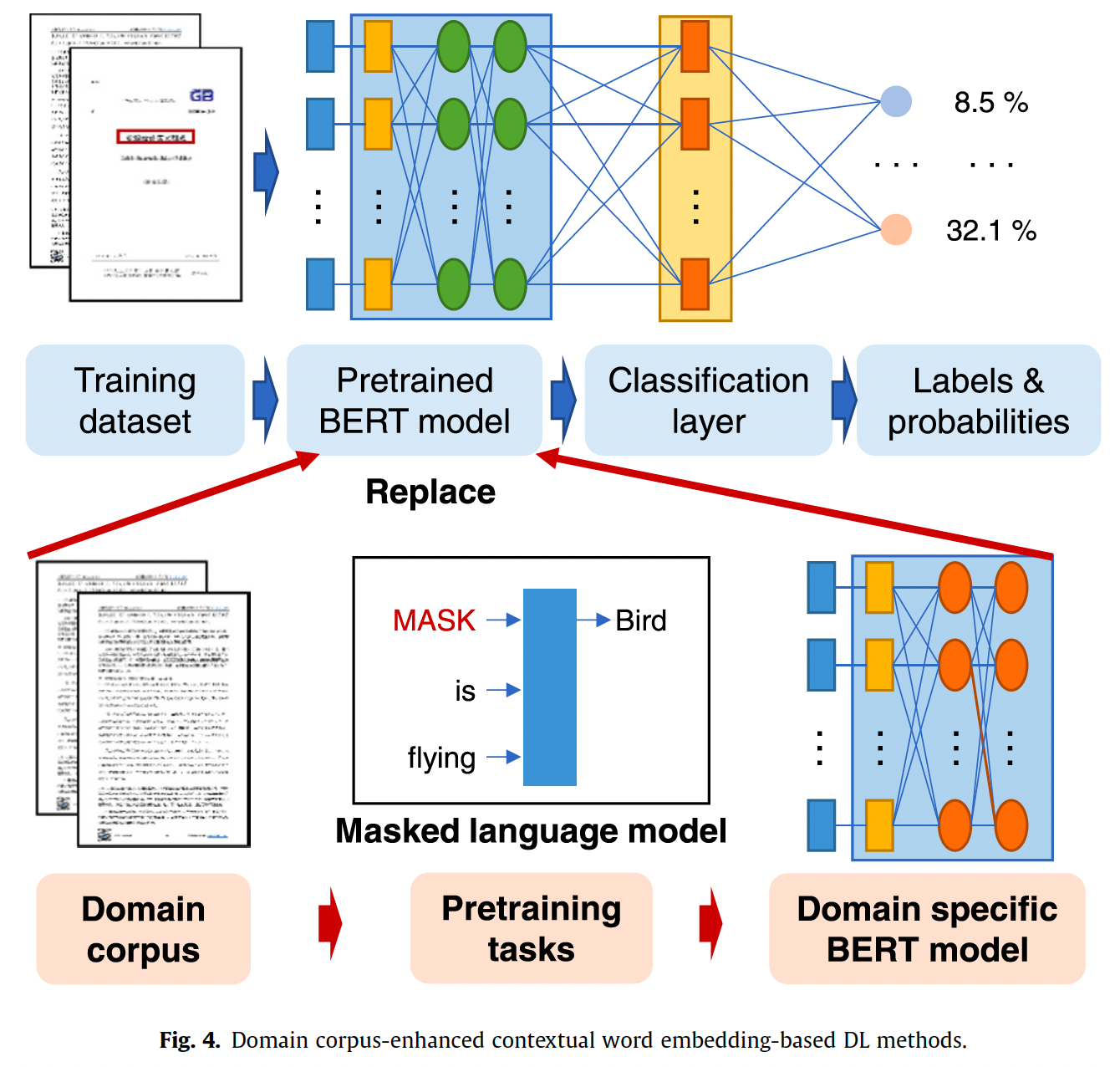
在确定了以上要素后,在specific-domain foundation model中存在“词表与通用领域不同”的问题,即可能某些词语在通用语料库中不存在,或具有歧义,因此模型的word embedding层需要替换为specific domain的词表。如下图所示采用skip-gram学习embedding。
主要参考文献
Kalyan, K. S., Rajasekharan, A., & Sangeetha, S. (2021). Ammus: A survey of transformer-based pretrained models in natural language processing. arXiv preprint arXiv:2108.05542.
3. Related work, after 2020
这里列出了大模型的训练算法、应对大规模模型参数的解法,应对分布式数据、环境的训练方法。有标注会议名称的论文均为顶会/领域顶会论文。
[ACL2022] BMInf: An Efficient Toolkit for Big Model Inference and Tuning
Xu Han; Guoyang Zeng; Weilin Zhao; Zhiyuan Liu; Zhengyan Zhang; Jie Zhou; Jun Zhang; Jia Chao; Maosong Sun
[KDD2022] Beyond Traditional Characterizations in the Age of Data: Big Models, Scalable Algorithms, and Meaningful Solutions
Shang-Hua Teng
[NIPS2022] Contrastive Adapters for Foundation Model Group Robustness
Michael Zhang; Christopher Re
[NIPS2022] Decentralized Training of Foundation Models in Heterogeneous Environments
Binhang Yuan; Yongjun He; Jared Quincy Davis; Tianyi Zhang; Tri Dao; Beidi Chen; Percy Liang; Christopher Re; Ce Zhang
[IMCL2021] PipeTransformer: Automated Elastic Pipelining for Distributed Training of Large-scale Models
Chaoyang He; Shen Li; Mahdi Soltanolkotabi; Salman Avestimehr
[IJCAI2022] Heterogeneous Ensemble Knowledge Transfer for Training Large Models in Federated Learning
Yae Jee Cho; Andre Manoel; Gauri Joshi; Robert Sim; Dimitrios Dimitriadis
- [MLSYS2021] Pipelined Backpropagation at Scale: Training Large Models without Batches
Atli Kosson; Vitaliy Chiley; Abhinav Venigalla; Joel Hestness; Urs Koster
3.1 大模型在垂直领域(定义在文本领域)的构建
[RECSYS2021] Large-Scale Modeling of Mobile User Click Behaviors Using Deep Learning
Xin ZhouYang Li
Lewis, P., Ott, M., Du, J., & Stoyanov, V. (2020, November). Pretrained language models for biomedical and clinical tasks: Understanding and extending the state-of-the-art. In Proceedings of the 3rd Clinical Natural Language Processing Workshop (pp. 146-157).
Xiao, C., Hu, X., Liu, Z., Tu, C., & Sun, M. (2021). Lawformer: A pre-trained language model for chinese legal long documents. AI Open, 2, 79-84.【中国法律长文档,做法律判决预测、相似案例检索、法律阅读理解和法律问答】
Beltagy, I., Lo, K., & Cohan, A. (2019). SciBERT: A pretrained language model for scientific text. arXiv preprint arXiv:1903.10676.【科学文本的语言模型】
Kierszbaum, S., Klein, T., & Lapasset, L. (2022). ASRS-CMFS vs. RoBERTa: Comparing Two Pre-Trained Language Models to Predict Anomalies in Aviation Occurrence Reports with a Low Volume of In-Domain Data Available. Aerospace, 9(10), 591.【航天事故文档,下游任务是关于故障种类的多分类问题】
Shen, J. T., Yamashita, M., Prihar, E., Heffernan, N., Wu, X., Graff, B., & Lee, D. (2021). Mathbert: A pre-trained language model for general nlp tasks in mathematics education. arXiv preprint arXiv:2106.07340.【数学文本中的语言模型】
3.2 大模型在垂直领域(定义在物理世界)的构建
- Zheng, Z., Lu, X. Z., Chen, K. Y., Zhou, Y. C., & Lin, J. R. (2022). Pretrained domain-specific language model for natural language processing tasks in the AEC domain. Computers in Industry, 142, 103733. 【建筑施工标准领域的语言模型】
- Zhou, Y. C., Zheng, Z., Lin, J. R., & Lu, X. Z. (2022). Integrating NLP and context-free grammar for complex rule interpretation towards automated compliance checking. Computers in Industry, 142, 103746.【上一篇的延续,从复杂合规标准中提取规则以做合规检验】
- Webersinke, N., Kraus, M., Bingler, J. A., & Leippold, M. (2021). Climatebert: A pretrained language model for climate-related text. arXiv preprint arXiv:2110.12010.【气候数据上的语言模型,其中有一个很有趣的例子是:Fact-Checking,即针对某个证据,由模型给出“该证据支持什么声明”的判断。】
- Berquand, A., Darm, P., & Riccardi, A. (2021). SpaceTransformers: language modeling for space systems. IEEE Access, 9, 133111-133122.【空间系统中的语言模型,根据空间标准制定,以concept recognization为最后的评估任务,这个任务应当被视为规范/标准类的基础任务】
此外还有一些大模型在多模态数据、针对大模型的security issue(like backdoor attack, etc.)等议题;在此不列出。